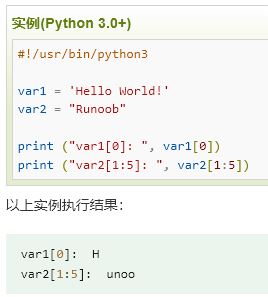
## 1.3 数据类型 详细讨论Python的各种数据类型,包括其特性、用途和示例。 --- ## 1.4 数据结构 介绍Python的常见数据结构,如列表、元组、字典和集合,以及它们的操作和用法。 ---
## 1.9 Python 面向对象 <font size=3> Python从设计之初就已经是一门面向对象的语言,在Python中可创建一个类和对象。 | 术语 | 描述 | | ---------------- | ---------------------------------------------------------------------------------------------------- | | 类(Class) | 用于描述具有相同属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。 | | 类变量 | 类变量在整个实例化的对象中是公用的,定义在类中且在函数体之外。通常不作为实例变量使用。 | | 数据成员 | 包括类变量和实例变量,用于处理类及其实例对象的相关数据。 | | 方法重写 | 如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override)或方法的重写。 | | 局部变量 | 定义在方法中的变量,只作用于当前实例的类。 | | 实例变量 | 在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但在类的其他成员方法之外声明的。 | | 继承 | 一个派生类(derived class)继承基类(base class)的字段和方法,允许将派生类的对象作为基类对象对待。 | | 实例化 | 创建一个类的实例,即类的具体对象。 | | 方法 | 类中定义的函数,描述了对象可以执行的操作。 | | 对象 | 通过类定义的数据结构实例,包括两个数据成员(类变量和实例变量)和方法。 | </font> --- ## 1.9 Python 面向对象 --- ## 1.9 Python 面向对象 --- ## 1.9 Python 面向对象 --- ## 1.9 Python 面向对象 --- ## 1.9 Python 面向对象 --- ## 1.9 Python 面向对象 ---